I have just been thinking recently about some of the reasons performance testing fails to stop performance problems occuring in the production environment. Below is a list of some of the reasons why performance testing can fail to spot these problems. Hopefully, the list below will provide, as a reminder of things to check next time you have to write a performance test plan. However, we must remember that like all testing, performance testing is about reducing the risk of failure and can never prove 100% that there will be no production performance problems. Indeed it may be more cost effective for some problems to occur in production than during test! Though your customer may not fully appreciate this approach.
So here is my list:
1) Ignoring the client processing time, performance test tools a designed to test the performance of the backend servers by emultating the network traffic coming from clients. They do not consider the delay induced by the client such as rendering and script execution.
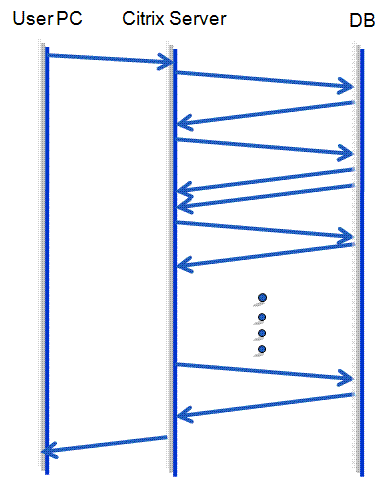
2) Ignoring the WAN, again test labs often inject the load across a LAN ignoring any outside the data center network delays. This is a particular problem for chatty application when it comes to network traffic.
3) Load test scripts that do not check for valid responses, performance testing is not functional testing but it is important that for the test script you write they check they are receiving correct responses back. The classic problem has been tools that just check that a valid HTML code is returned. The problem with this is that the “We are busy” page has the same valid code as the normal page.
4) Poor workload modeling. If we can not estimate the user workload correctly the load test will never be right. You might do a great test testing for 10,000 users but that is no real help if 20,000 user arrive on day one. Don’t under estimate the need to get a good workload model.
5) Assuming perfect users, alas users are not perfect and they make mistakes, cancel order before committing and forget to log off. This leads to a very different workload than if all the users where perfect, putting a different load on the environment.
6) Bad Test Environments, a test environment should be as representative as the production environment as possible. I have seen failures particularly when the test environment has been undersized but also where is has not been configured in a similar fashion to production.
7) Neglecting Go-live+10 days performance issues, Performance testing typically focuses on testing the peak hour and a soak test. What is difficult to do in a performance test is to represent how the system will be after several days of operations. Systems can ground to a halt as logs build up and nobody has got round to running the clean up scripts or transactions slow as SQL cannot cope with the increased rows in tables.
8) Unexpected user behavior, Very difficult to mitigate this one as it unexpected! However, in many cases a lack of end user training has resulted in users doing the unexpected like the car part salesman that didn’t know how to use the system and did a wild card search to return the complete part catalogue and then scrolled through it to find the part manually each time! Caused a killer performance issue.
9) Lack of statistical rigor. You don’t need to statistical guru to run a performance test but you should at least run the test long enough and enough times to be confident that the results are repeatable.
10) Poor test data, like the test environment the test data should be as representative as possible. Logging in all the virtual users with the same user id may put a different load on the system then if each had their own user id.